
天天德州腾讯版正版v1.4在哪能下载?这里有答案
2025年12月26日
你玩的APP游戏其实就是赌博
2025年12月26日
此次转载的文本,源自PingWest品玩,其ID为wepingwest 。
“我突然想起了一句话,神仙怎么打都是对的。”
这一AI所呈现的牌效,并非是那种普通的、称得上凤凰的具备一定实力的玩家就能够摸清楚状况的,而该玩家的人名乃是super phoenix,也就是超级凤凰 。
知觉到,人工智能的打法并不能全然被推理透彻,这般基于训练所形成的针对某种特征而展现出的反应,对于人类来讲,着实是令人困惑不解的呀…
这些评论源自B站上一个系列视频,视频的主角是一个叫Suphx的,其意为Super Phoenix的麻将AI,2019年6月开始有创作者制作Suphx牌谱的视频,上传至B站后引发了不少麻将爱好者的讨论。
在多数评论里,Suphx 被称为“最强日麻人工智能”。

事实上,不只是国内的B站,在当时,Suphx的声名,已然在日本麻将界得到广泛传布 。
神秘的最强日麻 AI
从2019年3月开始,获批进入专业麻将平台“天凤”的是Suphx ,在短短四个月里头,Suphx在该平台疯狂对战了5760次,进而成功达到十段,于是在日本麻将界声名大噪 。
在中国,麻将有着十分深厚的群众基础,其普及率很高,它还有着“国粹”的称呼,不过民间所流行的麻将规则并不统一,并且其竞技化程度相对来说比较低,然而呢日本麻将却拥有着在世界上竞技化程度最高的麻将规则,那天凤可是业界之中知名的高水平日本麻将平台,它吸引了全球差不多 33 万名麻将爱好者,其中有大量的专业麻将选手。
天凤平台有规定,获批准的AI才可进入“特上房”参与对战,此房间所能达到的最高段位是十段。还有个房间是“凤凰房”,其最高段位为十一段,仅对七段以上付费的人类玩家开放,当前不允许AI参与游戏。
有着别于Suphx的情况的是,另外存有着两个AI相继获得许准入到“特上房”比赛当中,它们分别是“爆打”以及“NAGA25” 当下,处于一种状态的是,Suphx成为了唯一一个达成“特上房”最高段位层级的AI 。
麻将单局存在极大运气成分,故而天凤平台借“稳定段位”衡量玩家真实水平,5760场比赛后,Suphx稳定段位超8.7,不但高于爆打与NAGA,且超越顶级人类选手(十段及以上)整体稳定段位 。
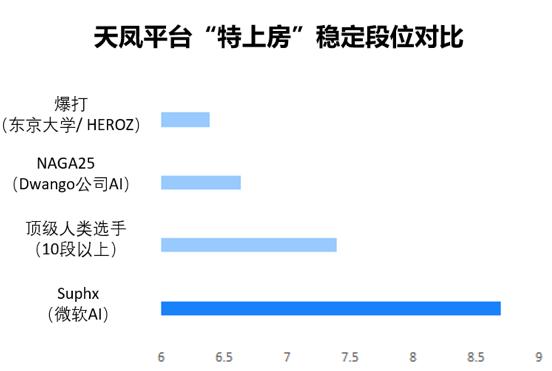
这些成果表明,Suphx 在四个月的时间里成长为了最为强大的日本麻将人工智能。日本麻将领域的爱好者以及专业参赛人员,都在纷纷寻觅它背后的开发者,然而却毫无所获。
(Suphx 的官方社交账号上,只有简单的介绍)
直到8月29日,世界人工智能大会举行了,Suphx的身世才被公之于众,在此之前它的真实情况一直处于保密状态。就在当天上午,微软全球执行副总裁,同时也是微软人工智能及微软研究事业部负责人的沈向洋博士对外进行了宣布,声称Suphx是微软亚洲研究院的工作成果,是由刘铁岩博士带领团队进行研发的。
中国科学院软件研究所客座研究员,微软亚洲研究院副院长刘铁岩博士,在深度学习、增强学习、基于概率模型的机器学习、分布式机器学习等领域颇有建树,其团队曾发布微软分布式机器学习工具包(DMTK)、微软图引擎(Graph Engine)等开源项目。

(微软亚洲研究院副院长刘铁岩)
对 AI 来说,为什么麻将比围棋、德州扑克更难?
洪小文,微软全球资深副总裁、微软亚太研发集团主席兼微软亚洲研究院院长,称在2017年中旬,有一个研究团队跟他讲要做麻将AI,他不清楚能否成功,鉴于麻将比象棋、围棋、德州扑克难度更高,且团队成员打麻将水平欠佳 。
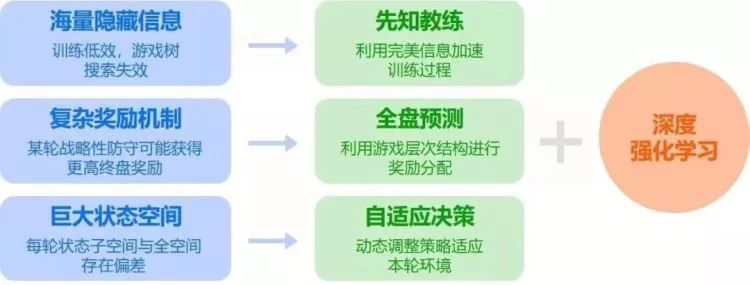
麻将有着难度,这难度在于它归属于“不完美信息游戏”,也就是Imperfect-Information Games,它使得计算机所擅长的搜索能力没办法直接施展,并且它还拥有复杂的奖励机制。
一种游戏,被称作不完美信息游戏,其描述为,在该游戏里,信息的暴露程度处于较低水平。像围棋、象棋这般的棋类游戏情况不同,对局之时,双方能够看到局面呈现出的所有信息,所以它们归属于完美信息游戏,也就是Perfect-Information Games;与之不一样的是扑克、桥牌、麻将等游戏,则属于不完美信息游戏,这是因为,就算每个参与者都能够看到对手已经打出的牌,然而却不晓得对手手中持有的牌以及游戏的底牌。
于日本麻将里,每位玩家持有十三张手牌,此外存有八十四张底牌。对一位玩家来讲,其仅晓得自身手中的十三张牌以及先前打出的牌,然而却没法知晓他人的手牌与未翻开的底牌。故而,最多之时一位玩家未知的牌超过一百二十张。
为了能更妥善地阐释不完美信息游戏,刘铁岩举了个例子,说道:“要是把围棋这般的(完美信息)赛事比作一棵游戏树,那么类似麻将这样的赛事就是由众多树构成的森林,参与者不清楚自己处于哪棵树上。”。
对于那种完美信息的游戏,一般能够借助“状态空间复杂度”,以及“游戏树复杂度”,去衡量它的游戏难度 。
称为“状态空间复杂度”的东西,是指游戏开始之后,在棋局进行的进程当中,全部符合规则的状态的总数量 ,“就像在棋类游戏那里,每挪动一枚棋子或者捕获住一个棋子,便创造出了一个全新的棋盘状态,所有的这些棋盘状态共同构成了游戏的状态空间” 。
有这样一种计算状态空间复杂度时最常用的方法,它包含那些不符合规则的状态,还包含那些不可能在游戏里出现的状态,通过做这些来计算状态空间的一个上界,也就是Upper Bound。像在估计围棋状态数目上界时,会允许出现棋面全部是白棋的极端情况,同时也会允许出现棋面全部是黑棋的极端情况。
游戏树复杂度,也就是GTC,它所代表的是所有不同游戏路径的数目,是一种衡量维度,这种维度比状态空间要复杂得多,原因在于同一个状态能够对应不同的博弈顺序。
微软亚洲研究院的博客给出了一个例子,具体是,在下图里,两边的井字棋游戏中,都存在着两个X以及一个O,它们属于同一状态,然而,这个状态有可能是通过两种不一样的方式形成的,并且,形成路径是由第一个X的下子位置来决定的。
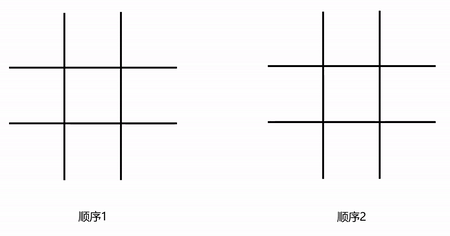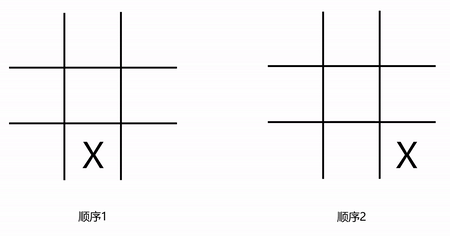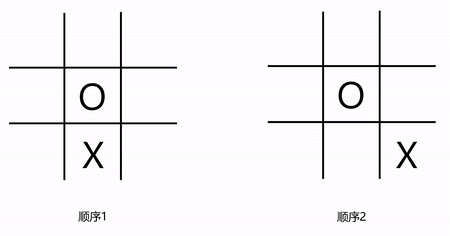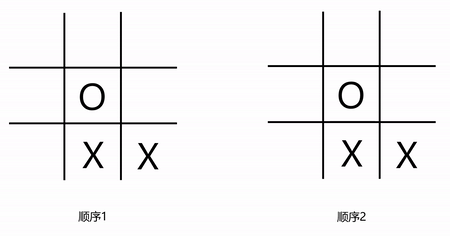
(井字棋游戏中统一状态的不同形成过程)
处于完美的,信息类之棋牌游戏里头;不管是那种状态方面,具有空间性质的复杂度;还是那种游戏树形式,可以表示过程的复杂度;围棋都显著地,远远地超出了其他的,属于棋牌类型的其它游戏。
然而,对于那种并非完全完美信息的游戏来讲,去衡量其游戏难度的维度会变得更为复杂,这首先得在状态空间复杂度的基础之上,再引人一个全新的概念,这个全新概念就是“信息集”。
打个比方,于扑克游戏里,玩家 A 拿到了两张 K ,玩家 B 则持有不一样的牌对应不一样的状态 ,然而从 A 的角度去看 ,这样的状态是没办法区分开来的 。
刘铁岩介绍道,我们将每组这种不能够加以区分的游戏状态称作一个信息集 。
在完美信息游戏之中,所有的信息都是处于已知的状态,每一个信息集仅仅只涵盖一个游戏状态,所以它的信息集数目跟状态空间数目是等同的。
在不完美信息游戏里头,每个信息集涵盖若干个游戏状态,所以信息集的数目通常小于状态空间的数目。
符合信息集数目适配情况的,是信息集的平均规模大小。该概念所表达的是,在信息集中平均来说德信竞技,存在着多少无法彼此区分的游戏状态 。
依照微软亚洲研究院博客所述,信息集的数量体现了不完美信息游戏里,全部能够存在的决策节点的数量,并且其平均大小反映出游戏中每一个场面背后隐匿信息的数目。在对手的隐藏状况极为众多时,传统的搜索算法几乎没有办法着手处理 。
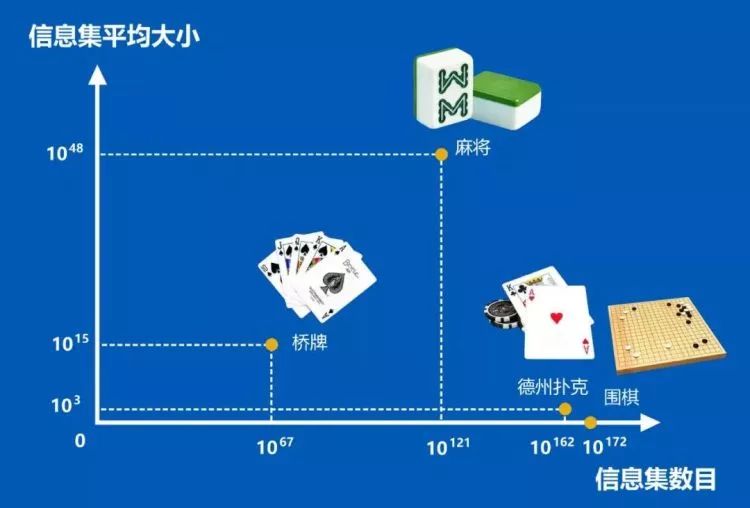
远远小于桥牌和麻将的,是围棋和德州扑克的信息集平均大小。AI在围棋和德州扑克上取得成功,很大程度依赖于搜索算法,因为借助搜索,能够最大程度发挥计算机的计算优势。
在桥牌里,还有麻将当中,鉴于信息集平均大小比较大,有着较多隐藏起来的信息,很难直接去采用像AlphaGo等棋盘游戏AI常用的蒙特卡洛树搜索算法。
而且,日本麻将具备繁杂的奖励机制。日麻一轮游戏总共含有8局,最后依据8局的得分总和去进行排名,进而形成最终对段位产生影响的点数奖惩。玩家的段位越高,输掉比赛后被扣掉的点数就越多,所以有时麻将高手会进行策略性输牌。
刘铁岩举例讲:“比如说,当A玩家早就大幅度领先第二名之际,在倒数第8轮的时候就会比较趋于保守,以此保证自身不会输掉。”这样一来就给构建非常高深的麻将AI策略增添了额外的难题,AI得要观察时机,拿捏住进攻与防守的恰当时候。
Suphx 是如何解决难题的?
在项目刚开始的时候,刘铁岩所带领的团队采用了一些被称作“基线(Baseline)的解决办法”,也就是试着运用于AlphaGo和德州扑克上用过的那些方法去进行解答,看看最终会是怎样的一种情况。
基于麻将所具备的种种特点,这就决定了,在直接运用 AlphaGo 等棋盘游戏 AI 常用的蒙特卡洛树搜索算法时会存在困难。刘铁岩着重指出,这一情况激励着我们,要去想出全新的点子。
在历经一年多的摸索阶段时,刘铁岩所带领的团队,是基于深度强化学习这一技术的情况,并且还引入了三项全新的技术,以此来提高强化学习所达成的效果。深度强化学习,它属于深度学习与强化学习二者相结合的产物。这项技术,它汇聚了深度学习在感知相关问题上具备的强大理解能力,以及强化学习所拥有的决策能力,一般是被用于解决现实场景之中的复杂问题的。
刘铁岩团队,基于深度强化学习,针对非完美信息游戏的特性,尝试运用“先知教练”技术,以此来提高强化学习的成效 。
先知教练技术的基本思想是,在自我博弈的训练阶段,有一些不可见的隐藏信息,要据此引导AI模型的训练方向,让其学习路径更清晰,使其更接近完美信息意义下的最优路径,进而倒逼AI模型更深入理解可见信息,从中找出有效的决策依据。
然而,在训练模型的阶段,所采用的是先知教练技术,而在真正的实际战斗当中,这个技术是不存在的,这就表明,训练与实战之间,存在着一个 Gap(差距)。
刘铁岩称,我们没法确保一定把那个Gap抹掉,比如说在训练阶段它能看到不该看到的事物,而在实战里它永远看不到,这个信息的Gap我们控制不了,不过作为先知教练能引导麻将AI不会偏离太远,会依照我们期望的大方向行进,这能保证训练过程的平稳性,对深度强化学习极为重要。
鉴于信息集均量规模相对较大这一要点而言,研究团队引入了自适应决策手段,针对探索进程的多元性予以动态调节,从而使得Suphx能够较传统算法更全面地探寻牌局态势的各异可能性 。
此外,针对日本麻将那繁杂的奖励机制,刘铁岩团队增添了全盘预测技术。
“这个预测器借助精巧设计,能够理解每轮赛事对终盘的各异贡献,进而把终盘奖励信号合理分配至每一轮赛事里,用以对自我博弈进程予以更具直接性与成效性的指导,还能让Suphx学到一些具备大局观的高级技巧。”刘铁岩作出解释 。
总而言之,Suphx 运用的是深度强化学习这一个大型框架之内,但另外增添了一些具备创新性的技术要点,有先知教练,有自适应决策,全盘预测也在其列。
Suphx 平台在 2019 年 3 月上线之前,背后那一套完整技术已然有了初步形态,并且开展了很多自我博弈,。
刘铁岩对 PingWest 品玩称,Suphx 在线上进行了 5760 场对战,然而在线下开展自我博弈的场次将近 2000 万场 。他还表示,虽说通过自我博弈学到的信号数量众多,不过学到更多的是关于在自身怎样去提高 。在那 5760 场对战里,学到了他人打法的风格,以及在实战当中碰到的困难该如何去解决 。
刘铁岩透露,研究团队有如此计划,过一段时间,会有一篇科学论文,这篇论文比较深入,会跟大家分享,“在那里面大家会看到更多的细节”。
Suphx 背后的技术可以用在什么地方?
随着AI向前发展,游戏AI始终如影随形。自1949年起,便有科学家钻研算法,以使计算机能够下国际象棋。双陆棋、国际跳棋、国际象棋以及围棋这类棋盘类游戏中,遍布着人机对战的痕迹 。
1997年5月11日,国际象棋AI深蓝于正常时限的比赛里,头一回击败了等级分位列世界第一的棋手,此日成了人机对战的里程碑 。
在洪小文眼中,游戏AI对于解决现实问题具备重要的研究意义,他表示,现实世界更为复杂,然而游戏都存在一个清晰的规则,还有胜负判定条件以及行动准则。要是不定规则,大家各自做各自的,便无法交流了。和研究是一样的道理,要把问题切成小问题,在小问题里面将规则清晰地厘定好,然后再继续向前推进。
麻将这类并非完美的信息游戏,恰恰体现现实际生活里诸多问题的映照,洪小文如此举例说我们追求女朋友时,存在数量众多的我们所不知的隐蔽相关信息,企业进行经营之时,也有大量的我们不清楚的潜藏信息情形,甚至于投资的过程中,同样有着大量的我们不晓得的潜藏了相关信息的状况。
苏夫克斯问世时间不长,其背后的全部技术尚未全都应用至实际问题里头,然而部分技术已然在开展尝试了。
“我们同华夏基金、太平资产展开合作,进行了一些实盘投资方面的尝试,收获了相当不错的成效。”刘铁岩讲道,“我们借助历史交易数据训练而成的AI模型,在真正落到市场上时会遭遇全然不同的数据,因而要在动态中适配实际场景并作出改变,这样的情况与Suphx里的自适应决策是有着内在联系的。”。
虽然最终目标是落地,然而洪小文觉得,对研究人员来讲纯粹的好奇心更为珍贵,他说:“开展这项研究之际,他们可曾思考过未来怎样去应用?大概是没想过,且不应当去想,由好奇心驱使的研究乃是推动整个科研进步的根基。最显著的例证是,基础数学的诸多研究在当时未必有应用。”。
具有趣味的情况是,于天凤平台处在 CEO 位置的角田真吾,当他被询问到“为何会对 AI 和人类进行对弈表示欢迎”这个问题的时候,所给出的措辞跟洪小文基本上是一样的,那就是完全源自于人类本身所具有的好奇心 。
该内容已取得独家授权,要是需要进行转载,那么得联系PingWest品玩(其ID为:wepingwest)。
