

扑克迷 |不同类型的失败!
2026年1月4日
德州扑克核心术语咋解析?还有啥策略应用?
2026年1月4日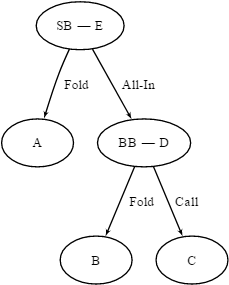
选自willtipton
机器之心编译
参与:Jane W、蒋思源
近些日子,强化学习也就是 RL 的出色成果就像 AlphaGo 那样赢得了大众极高的关注,然而它的基本想法是颇为简单的。接下来,我们要在一对一无限注德州扑克这个游戏里开展强化学习。为了能够尽可能清晰地呈现出来,我们会从毫无预设的状态开始去开发一个解决办法,这里并不需要像 Tensorflow 这类预设的机器学习框架。那就让我们借助 Python3 Jupyter notebook 开始着手吧!
问题设置
规则提醒:该游戏是一个 2 人无限注的德扑游戏,其中:
当游戏开启之时,存在两名参与的人员,这两名人员都持有 S 筹码,并且还拥有随机分配发放的 2 张底牌。
BB(大盲注)玩家进行下注,所下的注为 1.0 个盲注,SB(小盲注)玩家同样进行下注,其所下注为 0.5 个盲注。
小盲注的玩家,是能够选择全押这种行为的,或者是选择弃牌这种行为的 。
4. 若是小盲注玩家进行全押这种行为,那么大盲注玩家能够选择跟注或者选择弃牌 。
我们能够把规则可视作如下面所展示图形那样的决策树,游戏起始于E,在这个时候,SB能够选择全押或者弃牌,要是他选择弃牌,我们就会转移到状态A,此时游戏结束,要是他选择全押,我们就会转移到状态D,BB必须在跟注以及弃牌之间做出决定,如果有一个玩家弃牌,那么另一个玩家就会获取盲注,如果两个玩家都全押,那么就会发放5张公共牌,并且金额依照扑克的正常规则来进行分配 。
存在这样一款游戏,它有着声名远扬的解决方案,其网址正是(http://www.dandbpoker.com/preflop-charts),除此之外,还存有别的办法。比如说,有虚拟对局,对应的网址是(https://www.youtube.com/watch?v=MVMfDswjJE0),另外还有直接优化,其网址为(http://willtipton.com/coding/poker/2016/03/06/shove-fold-with-tensorflow.html)。这里,我们将使用强化学习估算解决方案。
这里存在着一种不会出现重复情况的,两张手牌所形成的组合数量。因而,我们能够针对所有的牌进行排序操作,并且从数字零开始一直到一千三百二十五进行编号处理。只要前后所对应的编号保持一致,那么具体的排列顺序其实就并不重要了。以下的这个函数暗地里已然定义了这样的一种排序方式,并且创建了从牌的编号一直到与之相关的决策信息之间的映射关系:牌的排序情况(牌面的顺序也就是rank)以及同花性(牌面的花色也就是suitedness) 。

要留意,输出出来的元组之中的首个元素(代码里的 r2)一直排序处于靠前位置,要是存在的话。举例来说,手牌编号 57 正好是 62,我们存在这样的情况:
在玩家进行全押操作的时候,他们所平均获取的底池,也就是所谓的「期望利益」,是依据游戏规则来予以决定的。置于 http://willtipton.com/static/pf_eqs.dat 的文件 pf_eqs.dat 里,存有一个名为 pfeqs 的 numpy 矩阵,其网址为 http://docs.scipy.org/doc/numpy-1.10.0/reference/generated/numpy.savetxt.html ,这里的 pfeqs 所指的乃是这样一种情况,也即当对手持有手牌 j 的时候,持有手牌 i 所具备的期望利益 。
当然,有的时候,两人起始手牌之中会存在一张相同的牌,处于这种情形下,它们的期望没办法同时进行计算,在这个时候,去取得他们的期望利益也是不合适的。文件pf_confl.dat(http://willtipton.com/static/pf_confl.dat)含有另一个1326×1326矩阵,其中每一个元素要么是0要么是1。A 0表明两位玩家的起始手牌是不一样的,a 1表明起始手牌是一样的。
比如说,鉴于手牌当中,56对应着62,57对应着62,58对应着62,所以我们便得到了:
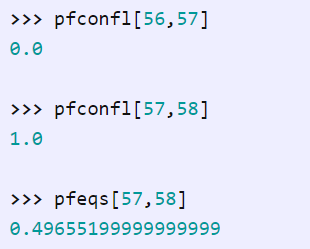
为什么结果不正好是 0.5 呢?
强化学习
接下来步入 RL 教程。RL 问题存有三个关键构成部分,分别是状态(state),动作(action),奖励(reward)。它们组合到一起呈现如下:
1. 我们处于某「状态」(即我们观察到的世界的状态)。
2. 我们使用这个信息来采取某「动作」。
3. 我们会得到某种「奖励」。
4. 重复以上过程。
将上述过程一遍又一遍地重复:对状态予以观察,随后采取行动,进而获得奖励,接着观察全新的状态,再采取另外一个行动,又获得另外一个奖励等等。RL问题仅仅是去找出究竟怎样选择行动的方案,以此来获取尽可能多的奖励。事实表明这是一个极为普遍的框架。我们能够借由这种方式去考量诸多问题,而解决这些问题同样存在许多各异的方法。通常来讲,解决办法关联随机游走,也就是于各异状态挑选各类行为,牢记哪些组合可获取何种奖励 ,接着试着借助这些信息未来做出更优选择。
RL怎样被用于德扑游戏呢,在任意决策点上,玩家清楚他的2张底牌以及他所处的位置,这些构成了状态,接着他能实施行动,要么选择弃牌,要么进行GII,GII对于SB而言意味着全押,也就是shove,对于BB而言意味着跟注,随后获取奖励,此奖励是玩家赢到的钱数,在最后的手牌里我们要运用玩家的总筹码大小,比如,要是初始筹码大小为S等于10,SB全押BB弃牌,那么玩家得到的奖励分别是11和9 。
对于游戏策略的探寻,我们会借助模拟手牌组合来得以获得。针对两个玩家的随机手牌,我们会进行同时处理,促使他们就如何玩作出决策,随后查看他们每次结束之际最终所获取的金钱数额。利用该信息,我们会用以学习(估计)Q函数Q(S,A)。Q的参数包含状态S以及动作A,其输出值是在该状态下采取该动作时所收获的最终奖励值。一旦我们拥有Q(或者它的某种估计),策略挑选就变得简单易行:我们能够对每个策略予以评估,从而判定哪一个更为出色 。
所以,这儿我们所进行的工作乃是估计Q,我们会运用Q^(其发音为「Q hat」)去指代这个估计。在初始化之际,我们会随机地猜测一些Q^。接着,我们会模拟一些手牌,两名玩家依据Q^做出决定。每一次手牌过后,我们会调整估计值Q^,用以体现玩家于特定状态下采取特定动作后所获取的实际值。最终,我们理应能得到一个效果良好的Q^估计,而这便是确定玩家策略所需的全部内容。
该注意的是,我们得保证在全部状态下采取全部动作,每个状态与动作的组合起码尝试一回,如此方可好好估计出最终每个可能的值。故而,我们会让玩家于一小段时间ε内随机地去行动,运用他们凭着当下估计得出的最佳策略。首先,我们得积极探寻选择的可能性,频繁地随机选。随着时间前行,我们会更多地借助所获知识。也就是,ε会随着时间推进而收缩。有好多法子能达成这,像:

称作「动作价值函数(action-value function)」的是Q,因基于任何状态采取任何特定动作的值由它给出,它在多数RL方法里有重要作用,Q^怎样表示,如何进行评估,是不是在每次手牌之后更新 ?
特征:Q^ 的输入
首先,Q^的输入是状态和动作,把这个信息传递给Q函数,作为位置,像SB为1,BB为0那样,及手牌编码,从0到1325,还有动作,比如GII为1,弃牌为0。然而,我们将会看到,要是我们做更多的工作,便会得到更好的结果。在此处,我们用7个数字的向量来描述状态和动作:

由函数phi返回的向量φ会作为Q函数的输入,此向量被称作特征向量,其各元素均为特征(φ发音为「fee」),我们将会看到,我们所挑选的特征能够在结果质量方面造成极大差异,在名为「特征工程」的筛选特征过程中,我们运用了与问题相关领域的知识,它同科学一样具备艺术性,在此处,我们选用以下几种方式对判断哪些为(在这种情形下)相关信息的知识进行编码,让我们一同查看 。
为了方便,第一个元素一直是1 ,考虑随后的四个元素 ,这些是玩家手牌的代表 ,我们从手牌编码转为了rank1、rank2和isSuited ,这三个变量在技术意义上给出把手牌编码一致的信息(忽略特定组合) ,但该模型会更优 使用这种格式的信息 ,除了原始排序 ,我们纳入了(|rank1 – rank2|)^0.25 ,我们恰好晓得connectedness是德扑的重要属性 ,就像其名称一样 。除此之外,要是所有的特征在量纲方面保持一致,那么该模型的学习成效将会更为出色。在这个地方,所有的特征大体上处于0与1的范围区间内,这是我们借助把rank除以numRanks而获得的结果。
最终,要是 not isGII(也就是动作是弃牌的情形下),我们事实上是把这些数字设定为 0 。我们清楚,当玩家进行弃牌操作时,特定的持有手牌对于结果是不存在任何影响的(将小概率的卡牌移除效果忽略掉),所以在这种情景之中我们把无关的信息给删除掉了。
现在思考一下最后那两个元素,第一个元素直接对玩家的位置进行编码,然而第二个元素同时依赖于isSB以及isGII,为何会呈现这样的情况呢,等到稍后的时候我们会展示出这个“交叉项”的必要性。
关于 Q^ 的线性模型
我们会去学习一个用来进行估计的线性函数的Q^函数,这表明啥,这意味着我们要切实学习一个参数向量 ,这个参数向量一般被称作θ ,它的长度是(7) ,和特征向量长度一样 ,之后 ,我们会针对特定的φ去估计Q^ :
在这里,下标 i 用来指代向量的特定元素,并且把参数列表写成 (φ;θ),这意味着 Q^ 的值由 φ 和 θ 所决定,不过我们能够把它看作是 φ 的函数,而 θ 是固定不变的值。代码十分简单:

虽然这个函数被广泛运用,可是这个算法并无突出之处,无法让它成为此问题的最佳选项。这仅是一种方式:将某些学习参数与某些特征配合以得到输出,而完全由我们去定义一个θ向量,让它产生我们期望的输出。然而,正确挑选θ会为我们精准估计在有特定手牌时采取特定行动的价值 。
模拟扑克游戏
我们接下来要着手于「玩」手牌这个行为了。之后过程会在接下来相连的几个部分里开展进行,然而此刻我们要先去构建起三个具有关键意义的概念。这三个概念是和RL问题的三个极为重要的构成部分相互关联的,分别是:状态、动作以及奖励。开始先说状态,对于每一次的手牌而言,我们会运用随机发牌这种形式来对每一位玩家的状态予以初始化。

这是第二点,要采取动作。每个玩家会去使用当下的模型,这个模型是由theta给出的,同时玩家还已知手头的牌以及自身的身份,身份处在为SB的情况,基于这些条件来选定动作。在下面的函数当中,我们会对GII以及弃牌/FOLD,也就是qGII和qFOLD的值进行估计。接着去挑选当下的最优项,是(1 – ε)这种情况,不然就随意随机地去选择动作。最后返回所采取的那个动作,以及这个动作相应的价值估计和特征向量,而这两项我们在之后是会用到的,。
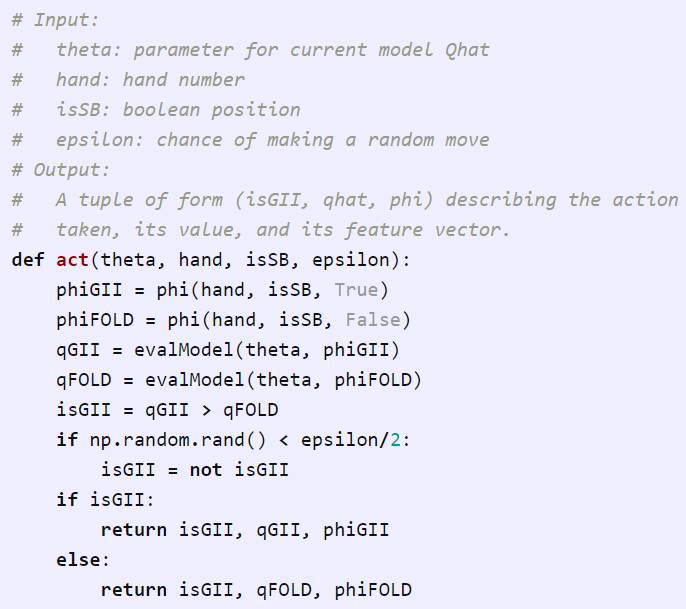
首先是第三点,一旦我们清楚知晓每个玩家当下所拥有的手牌以及其做出的动作,那么我们便会模拟剩下的手牌以此来获得玩家的奖励;要是存在任何一个玩家弃牌,我们能够即刻返回正确的奖励值;不然的话,我们会参考玩家的状态以及奖励期望(公平性),在正确的时间段随机挑选出一个赢家 。
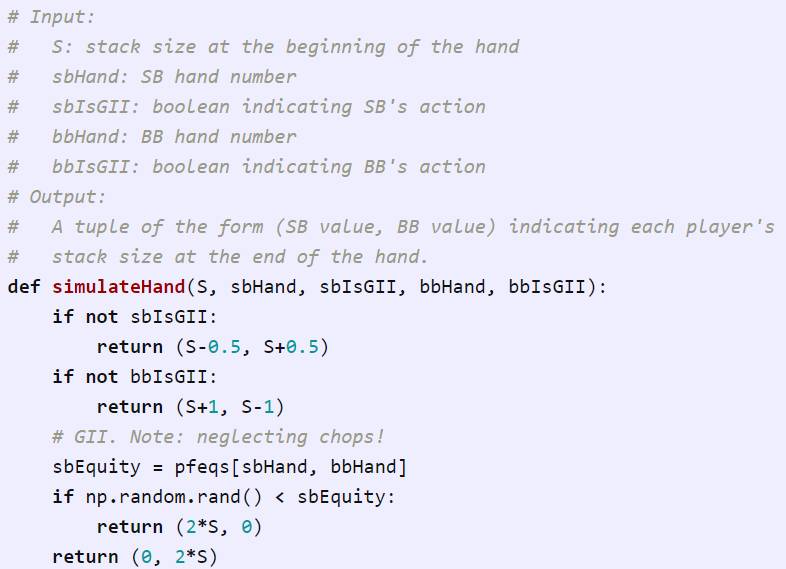
当玩家以全部筹码进行押注时,我们借助小伎俩避开了模拟。不同于利用五张公共牌切实模拟游戏,评估玩家手中卡牌以判定输赢,而是如今依据预先算出的概率随机挑出一个获胜者。此在数学层面是等同的(繁复的证明予以略过),仅仅是一种更为便捷且具备计算效率的方式。
最为关键的是,我们于学习进程之中,并未运用这些公平性或者关乎游戏规则的信息。就如同我们即刻即将目睹到的这般,即便属于全然模拟,学习过程也不存在差异,甚至智能体还会跟外部黑盒的扑克游戏系统展开交互,进而有可能遵循各异规则!那么,学习过程到底怎样开展呢?
学习:更新 Q^
一次手牌结束后,我们要更新theta,对于每个玩家,我们知晓其状态与采取的动作,我们还有动作对应的估计价值以及从游戏中得到的实际奖励,从某种意义来讲,实际获取的奖励是「正确解」,要是动作的估计价值与之不一样,那我们的模型就有误,我们需更新theta,让Q^(φ;θ)更靠近正确的答案。
让 φ’ 成为一位玩家所处的特定状态,R 是她所获取的实际奖励。让 L 等于(R 减去 Q 的 φ 分号 θ 次方)的平方。L 被称作损失函数。L 越小,R 就越靠近 Q 的 φ 分号 θ 次方,要是 L 为 0,那么 Q 的次方就恰好等同于 R。也就是说,我们要微化调整 θ,让 L 变得更小。(留意,存在许多可能的损失函数,致使随着 Q 的次方越来越趋近于 R,L 越来越小。这里的损失函数只是一种常见的选取)。
所以,「更新Q」所指的,是通过改变θ,进而使得L变得比之前更小,存在不止一种能够达成这一情况的方式,其中一种较为简便的方式被称作随机梯度下降(stochastic gradient descent),简单概括来讲,这种方式用于更新θ的规则是:
我们要去挑选「超参数」α,它被称作学习率,其能够把控每次更新的幅度。要是α过小,那么学习速度会十分缓慢,然而要是它过大,那么学习过程有可能无法收敛。把L代入到这个更新规则之中,并且开展几行微积分计算,我们就得到。
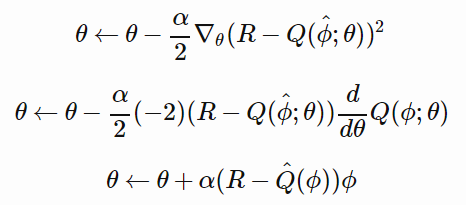
代码编写会依据,最后一行所提供的,更新参数的准则来进行,要留意,这里的θ以及φ,均为长度是7的向量,并且,这里更新参数的准则,是分别适用于每个元素的。
整合
最后,该整合所有内容了。重复以下步骤:
1. 随机发给每个玩家手牌。
2. 令玩家各自选择一个动作。
3. 得到结果。
4. 使用观测到的(状态,动作,结果)元组更新模型。
如下的函数,名为mc,它达成了这般的蒙特卡罗算法,且返还出学习模型的参数theta 。

特别注意,上节推导出的参数更新规则在代码中得到了实现。
结果
解释模型
本例中,固定 S=10。
数字,我们已然获取,然而,它们究竟有无意义呢?实际上,存在着若干种方式,能够助力我们去进行判断,并且借助它们,从而获得一些关于模型的解释。
首先,我们思索某些特定的情形。当SB进行弃牌(即FOLD)之际,其估计数值是多少呢?很轻易能够获取,鉴于处于这一情形下φ相对简易。实际上,除开第1个(固定为1)以及第6个(对应着isSB)以外,所有的元素均为0:phi =。
1,0,0,0,0,1,0
所以,我们的线性模型的Q^,其内容仅仅是相当于,去对theta的第1个元素以及第6个元素进行加总,。
此时此刻,我们已然清楚,依据游戏所设定的规则,SB做出弃牌这一行为所具备的价值为9.5 ,故而,极其酷炫的是,模型跟真实状况极为贴近 ,这属于一种相当不错的逻辑判断 ,并且借助例子展示了怎样去估量我们模型有可能出现的误差值的大小 。
再一种情形是,BB选择弃牌,仅有phi的开头那个元素并非零值,我们找出一个估计数值,。
虽然并不清楚正确答案究竟是什么,只是除了晓得它肯定应当在9(要是SB始终是GII)和10.5(要是SB始终弃牌)之间。实际上,这个数字相较于10.5而言更靠近9,这跟SB更倾向于GII而非相同是相符的。
有一种用于思考每个 θ 输入的更具一般性的方法,每个元素 θ_i 会致使 Q^ 出现增加,理由是与之对应的特征 φ_i 会增长 1,比方说,在存有合适手牌并同时施行 GII 策略之际,θ 的第 5 个元素会增添 1,所以,具备适合手牌的估计奖励值为 0.22571655,这是一个较小的正向奖励,看起来是合乎情理的。
θ的第2个元素,对应玩家排名较高的手牌,是6.16764962,这对应特征,若isGII则为rank2/numRanks,否则为0,意为玩家排名较高手牌时的GII策略,这里rank2除以numRanks,所以特征每增加1约等于2和ace之间的差,以一个额外的6 BB加上1个ace而不是2来取得胜利似乎是合理的。(但是,为什么你会觉得有第二张更高的手牌显然是负的?)
查看与第6个特征相对应的θ的元素,若isSB为1,其值为1,若isSB不为1,其值为0。,当所有其他特征都一样时,在SB中的附加值明显是 -0.15230302。我们有可能把这诠释成位置方面的劣势,此乃因不得不先行采取行动而产生的小惩罚 。
然而,其他的所有方面并非必然是一样的情况 。要是SB去执行GII策略,那么最后一个特征同样不是零 。所以,-0.15230302就是SB执行弃牌时所具有的附加值 。在执行GII的时候,我们对最后一个特征的贡献进行总结,发觉奖励是-0.15230302 + 0.14547532 = -0.0068277 。非常明显,当SB采取更为激进的策略时,位置方面的劣势就减少了!
于此我们见到,于该问题范畴之中,甄选具意义之特征能够助力我们有效地阐释结果。饶有趣味的是,存有一种名为SAGE的陈旧规则以供玩德扑游戏。此规则于锦标赛现场易于被记取。其原则乃是,为你的手牌构筑「能力指数」,它依据顺子、同花以及对子来进行规则构造,随后借助它去判定是否GII。它们的特征组合跟我们的特征组合相较状况如何?它们所得结果又是怎样?
最终,为何我们选用isSB以及isGII去判定最后一个特征,而非仅仅用isGII呢?对此展开思考。(BB,FOLD)的估计数值仅仅是θ的第1个元素德信竞技,因而这个第1个元素得能够随意变动,以此获取正确的(BB,FOLD)值。那么,第6个元素是在SB里的额外贡献,它需要能够随意变动来获取正确的(SB,FOLD)。
一旦我们从弃牌这件事转换到 GII,元素 2 变为非零状态,元素 3 变为非零状态,元素 4 变为非零状态,元素 5 变为非零状态,并且依据玩家情况调整为特定的值,然而这些决策同样适用于 SB,也同样这种决策适用于 BB。该模型需要为 SB 全押给出一些和 BB 全押不一样的决策。
假设,我们最终呈现的特征是这般的,如果处于isGII的状态,那么对应的数值就是1,要是并非如此,也就是处于非isGII状态时,此时对应的数值就是0 。它是不依靠玩家来作抉择的,所以,在SB和BB的估计值之间,唯一存在的差异将会体现在isSB这一项上面。这个具体的数字,是必须要将在执行弃牌这个行为时,SB和BB二者之间所存在的差异考虑进去的,同时,还得把在执行GII这个行为时,SB和BB二者之间所存在的差异也考虑进去。而模型,必须要在这两个差异之间去挑选出一个数字来,然而最终的结果很有可能就会导致出现一些并不理想的折中情况。与之相反的是,我们所需要的情况是这样的,如果同时处于isGII以及isSB的状态,那么对应的数值便是1,要是不满足这个条件,也就是并非同时满足isGII以及isSB ,那么对应的数值就是0 。如此一来,该模型能够分辨出SB GII和BB GII的增量数值,是这样的情况,用这种方式,是这样的状态 。
留意,此模型依旧没办法捕捉诸多细微的详情。举例而言,鉴于模型全然内置的函数形式,我们所见到的GII的估计值的差别在两种特定手牌组合情形下,像A2以及K2,对于SB和BB是确切相同的。不论θ的值怎样,我们的模型都绝对无法预测。
有着很高偏差值(bias)的这样的模型,它是不灵活的,而且还存在一个强大的内置「观点」用以决定结果会呈现出怎样的样子,这便是特征工程如此重要的缘由。要是我们未曾尝试给算法提供精心设计的特征,那么它或许就不具备表征一个良好解决方案的能力。
可为模型增添更多特征,像其他交叉项那样,借此获取偏差较低的模型,然而这兴许会引发缺点,这会迅速丧失可解释性,还可能遭遇更多技术问题,诸如过拟合,当然,在多数运用中这并非首要问题,准确性比可解释性更为重要,并且存在处理过拟合的办法。
可视化策略
我们要找到完整的策略,会对该模型进行评估,目的是了解在每个玩家的1326种手牌组合当中,是GII更好,还是弃牌更好呢,。

似是这样,针对于 SB 而言,大概有 55%的手牌其会去考量选择全押来应对,然而针对于 BB 来讲,大约 49%的时段会选择跟注,。
最终,我们能够产生一些 SVG,用以于 Jupyter 环境里绘制 GII 范围, 。


该如何进行选择呢?此地存在诸多我们所期望的定性特征,诸如,大的手牌状况良好,拥有对子为良好,同花情形比不同花更为有利,SB的打法相较于BB更为宽松等。然而,位于边界线的手牌打法,在某些时候,会与真正的平衡策略中的打法存在差异。
结语
这片介绍应用 RL 技术的文章,给我们提供了一些进行德扑游戏的合理策略。该学习过程不依赖任何结构,也不依赖游戏规则。它纯粹通过让智能体自行游戏,观察结果,再据此做出更好决定。另一方面,重要特征工程要学习一个好的模型,需一些领域专业知识 。
接下来,讲一讲一些背景情况。诸多恰当合理的问题能够被表述成RL问题,而且存在好多不一样的办法去处理它们。此处的解决办法也许具备以下这些特点:没有模型的,基于价值的,蒙特卡罗的,请留意,是在策略方面有特定规定的,没有进行折现处理的,并且运用线性函数逼近器 。
