
网络游戏《JJ游戏》被指赌博,玩家输光与妻子分居。
2026年1月12日
德州扑克冠军范云翔分享冠军生活哲学,成新一代时尚宠儿
2026年1月12日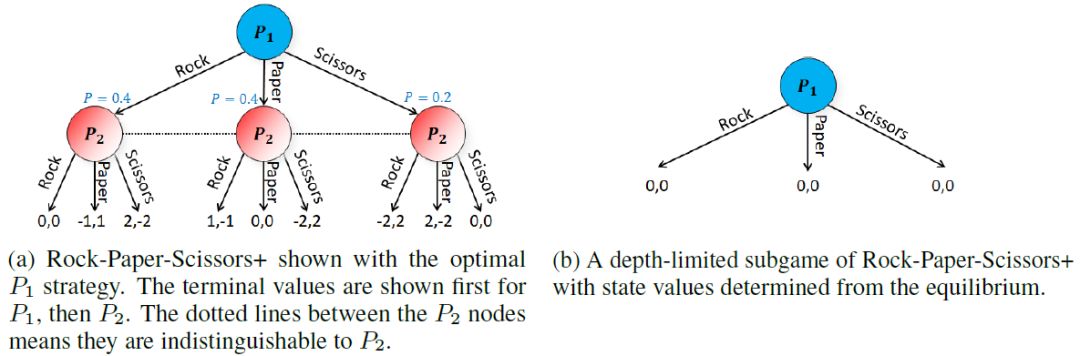
选自arXiv
机器之心编译
参与:路、晓坤
近日,CMU冷扑大师团队中,在读博士Noam Brown,以及Tuomas Sandholm教授,还有研究助理Brandon Amos,提交了一项新研究,该研究是关于德州扑克人工智能Modicum,它仅仅凭借一台笔记本电脑的算力,就战胜了业内顶尖的Baby Tartanian8,也就是2016计算机扑克冠军,它还打败过Slumbot,即2018年计算机扑克冠军。之前,名为《Safe and Nested Subgame Solving for Imperfect-Information Games》的冷扑大师的论文,是NIPS 2017的最佳论文。
1 引言
对智能体与隐藏信息之间战略互动予以建模的是不完美信息博弈,此类博弈的主要基准是扑克,特别是一对一无限注德州扑克,也就是 HUNL,在 2017 年人工智能 Libratus 击败了德州扑克的人类顶级玩家,带来这一超人性能的关键突破是嵌套求解,随着在博弈树的位置日益下移,智能体实时重复计算更为精细调整的策略,而该策略仅属于完整博弈的一部分。
但是,实时子博弈求解在 Libratus 的前半场会致使成本过高,它实时求解的那部分博弈树也就是子博弈常常会延展至游戏告终 。所以在 Libratus 的前半场会预先算出一个精密策略作为查找表。倘若该策略成功,那么就能够从中获取数百万核心机时用于计算,数 TB 之多内存在内存中存放可供使用 。另外,在更深层次的序贯博弈里,该方法的计算开销会更加高昂,这是由于求解的子博弈较为漫长,预计算策略规模更大所导致的 。有一种方法更为通用,此方法是,去求解子博弈,这些子博弈在博弈早期阶段,其深度是有限的,也就是进行深度有限的子博弈求解 。
一项与嵌套求解类似的技术被扑克AI DeepStack用于实现这种操作 。然而,虽然DeepStack战胜了一组HUNL非顶尖人类专业选手,可它未曾打败之前顶尖的AI,尽管它花费超过一百万核心时间去训练智能体,这显示出它所采用的方法或许在扑克等领域不够实际或者有效。本论文在第7部分对该问题进行了详细探讨 。有一种深度有限求解方法,它与其他方法不同,本论文对其进行了介绍,这种方法打败了之前处于顶尖水平的AI,并且在计算开销方面实现了数量级的降低。
叶节点处的值,于完美信息博弈里,在深度有限子博弈的情况下,被替换成所有选手于均衡状态时的状态估计值 。比如说,backgammon 、国际象棋 以及围棋 上,该方法达到了超越人类的水平。同样的方法,还在单智能体设置中,像是启发式搜索那样,被广泛应用 。
29, 24, 30, 15
确实,于单智能体以及完美信息多智能体的设定情形里,知晓所有选手处于均衡状态之际的状态数值,这就足够用以重建均衡了。然而德信竞技,此方法在不具备完美信息的博弈当中是没有成效的。
2 深度有限求解在不完美信息博弈中遇到的挑战
处在不完美信息博弈里边,(此亦称部分可观测游戏),但这子博弈里最优策略,没法经由知悉所有选手均衡状态之际的状态值,(也就是博弈树节点)来予以确定。图1a是一幅简单图示,它展现出一种序贯博弈游戏,名为「剪刀石头布+」,(通称Rock-Paper-Scissors+,简称为RPS+)。RPS+跟传统的RPS是一样的,只是玩家出剪刀时,赢者获得者2分而非1分,(输者同样输2分)。图1a把RPS+游戏以序贯博弈的形式来展示,P_1是首先进行动作的,然而却没有把动作透露给P_2。在这个游戏里,针对两个玩家而言,最优策略也就是Minmax策略,也就是双人零和博弈当中的纳什均衡,是每一方用40%的概率去选择石头或者布,用20%的概率去选择剪刀。在这个均衡状态下,P_1选择石头的期望值是0,选择剪刀或者布的值同样是0。这就是说,图1a里所有的红色状态在这个均衡里的值都是0。当下,假定 P_1 开展深度为 的深度有限搜索,深度极限处的均衡值被更替,此深度有限子博弈如图 所示,显然,在这个子博弈里不存在足够的信息达成 石头、 布、 剪刀的最优策略。

在RPS+例子当中,核心问题存在于,我们不正确地进行了假设,即P_2总是会执行固定的策略。要是实际上P_2出石头、布以及剪刀的概率是那样,那么P_1将会选择任意的策略,并且其期望值为0。然而,要是假设P_2总是执行固定的策略,P_1有可能无法找到对P_2变化具备鲁棒性的策略。实际上,P_2的最优策略依赖于P_1选择石头、布和剪刀的概率。大体来讲,于不完美信息博弈里头,玩家处在某一决策点时的最优策略,是依存于玩家在状态方面的信度分布,也就是信念分布,还有其他智能体于该决策点之上所采取的策略哟。
在本文当中,研究者引入了一种深度存在限定的求解办法,以此来保证玩家所采用的策略,对于对手出现的变化能够具备稳健性。研究者准许对手于深度存在一定限度的情境下,去开展最后一次动作的抉择,这里面每个动作都对应着对手将会于博弈剩余部分所施行的策略,并非是在深度达到极限之处单纯地更替逐个状态的值。策略的挑选会对状态值产生决定作用。对手并非依照特定于状态的方式来做选择,也就是并非选择最大状态值。相反,自然而然地,对手必须在所有状态里进行相同的,对他来讲难以区分辨别的选择。有研究者进行了证明,对于对手若被给予在深度有限之处的足够数量的策略这种情况,那么于深度有限之处的任何子博弈求解,都是完整博弈的纳什均衡策略的其中一部分。他们并且还借助实验进行了事态展示,当仅仅被提供了少量的策略之时在这里主要目的是为提高计算速度,该方法的性能能够达到极端的高度 。
6 实验
实验是研究者构建的,在一对一无限注德州扑克里,也就是HUNL,还有一对一无限注flop扑克那里,即NLFH。附录B里有这些游戏的规则。HUNL是不完美信息博弈AI的主要大规模基准。NLFH跟HUNL相似,只是博弈在第二个回合之后会马上结束,这就让它规模小到能精确算出最佳反应和纳什均衡。性能用mbb/g测量,这是文献里的标准胜率度量。milli-big blinds per game也就是mbb/g,它所代表的是玩家于每一手牌当中,平均能够赢取的大盲注(玩家在起始之时必须承诺的赌注)的千分之一 。
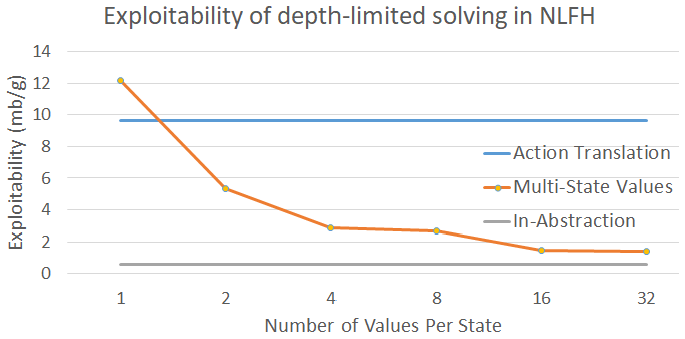
图2,回应对手的off – tree动作的深度有限解决方案的利用度,此利用度是作为状态值数量的函数,研究者进行比例对比,对比了动作转换,以及在动作提取中包含off – tree动作的办法,该包含动作在CFR +的1000次迭代的实现利用度是下限值。
6.2,在一对一,而且是无限注的德州扑克(HUNL)这个项目上,开展对抗顶尖AI的实验。
我们开展的重要实验方式属于深度有限求解的办法。同时,只用平常笔记本电脑内里的计算相关资源造就出了大师级别的HUNL扑克AI,那就是Modicum。我们针对Modicum同Baby Tartanian8以及Slumbot进行了测试。其中,Baby Tartanian8是2016年度计算机扑克竞赛的胜出者。而Slumbot是2018年度计算机扑克竞赛的获胜者。Slumbot 以及 Baby Tartanian8 均未运用实时计算,它们所采用的策略皆是于预先计算好的查找表当中进行搜索而后获取的,Baby Tartanian8 运用了大约 250000 个核心计算小时以及 2TB RAM 去计算策略。与之相反,Modicum采用的计算策略是,仅使用700个核心计算小时以及16GB的RAM,在运作时,它于配备4核CPU的情形下,能够以人类专家的速度实时开展博弈,具体表现为平均每一手扑克所需时间为20秒。
7 对比先前研究工作
本论文介绍了一种克服这一挑战的方法,该方法是通过为状态分配多个值,一种不同的方法是把「状态」的定义修改为所有博弈者对状态的信念概率分布,也就是我们所说的联合信念状态,这种技术以前还曾被用来开发扑克 AI DeepStack,对于我们所测试的领域,实验显示使用多值状态能够产生更好的性能。就比如说,我们所采用的方法,在核心计算小时少于1000个的这种条件之下,能够战胜两种以往顶级的德州扑克AI 。相比较而言,尽管DeepStack击败了在HUNL中并非那么专业的人类专家,然而它即便运用了1000000个核心计算小时,却也无法击败以前顶尖的AI 。但是,这两种方法都分别有着各自的优点与缺点,我们需要依据领域正确地去进行选择,未来的研究或许会改进它们的性能以及优势。
