

德州扑克升级必看!掌握这三个基本技能
2026年3月18日
去百度打开赌博网站贴吧,为海外赌博公司招聘客服人员。
2026年3月18日
科学杂志那有关此项研究的论文链接是,https://science.sciencemag.org/content/early/2019/07/10/science.aay2400。
Pluribus 基于 Libratus,还有其他一些算法、代码做了几项改进,Libratus 在 2017 年于双人无限注德扑里击败了人类顶级选手(参考:《学界 | Science 论文揭秘:Libratus 怎样在双人无限注德扑中战胜人类顶级选手》),这些算法以及代码是由 Tuomas Sandholm 带领的那个卡内基梅隆大学研究实验室所开发的。
需要指出的是,Pluribus 融合了一种全新的在线搜索算法,该算法能够借助搜索前面的几步,而非仅仅搜到游戏结束,以此来高效地评估其决策。另外,Pluribus 运用了速度更为快捷的新型 self-play 非完美信息游戏算法。上面这些提到的改进,让利用极少的处理能力以及内存来训练 Pluribus 变成了可行之事。训练所使用的云计算资源总的价值还达不到 150 美元。这种高效,与最近其他人工智能里程碑项目鲜明对比,后者训练,往往要花费数百万美元计算资源。
这些创新的意义,远远不止停留于扑克游戏之中,因为双玩家零和交互,也就是一输一赢的情况,在娱乐游戏里极为常见,然而在实际生活内却相当罕见。现实世界里的,诸如对有害内容采取行动、应对网络安全性挑战、管理在线拍卖以及导航流量等,通常会涉及多个参与者,并且或者隐藏着信息。多玩家交互,给过去的AI技术,提出了严峻的理论以及实践方面的挑战。Facebook的结果显示,一个精心构造而成的人工智能算法,能够在两人以上的零和游戏当中,超越人类的表现。
在 6 人扑克中获胜
相比于过去典型的游戏中,6 人扑克有两个主要挑战。
不只是简单的双人零和游戏
过去,所有游戏里存在突破限制于二人或者两队的零和竞赛,比如象棋、西洋棋、星际争霸2或者Dota2。在这些比赛当中,AI之所以成功,是由于它们尝试评估运用Nash均衡策略。在双人和双队的零和游戏里,不论对手做什么,作出精确的纳什均衡就有可能不会输掉比赛。例如,石头剪刀布的纳什均衡策略是以相同的概率随机选取石头、布或剪刀。
不管在何种有着限制的游戏里,都有着纳什均衡存在,然而,一般情况下,在有着三个或者更多玩家参与的游戏之中,想要有效计算出纳什均衡是困难的。(两人一般和游戏亦是这样的情况)另外,在多于两个玩家参与的游戏里边,就算做出了精准的纳什均衡策略,也存在输掉比赛的可能。比如,在Lemonade Stand game这个游戏里,每个玩家会同时在一个圆环上挑选一个点,而且又想着尽可能地远离其他任何玩家。纳什均衡是所有参与者沿着环间隔相同的距离,可是达成这个均衡存在着诸多方式。要是每一个玩家单独去计算当中的一个平衡点,那么联合起来的策略不太容易致使所有玩家依照那个环把距离等间隔拆开。就如同下面这个图呈现的样子:

有人思考,除了双人零和游戏,纳什均衡的缺点引发的问题是,这种游戏的正确目标究竟该是什么?
六人扑克里,研究者觉得其目标并非特定的游戏理论解决概念,而是打造一个长期可以凭借经验战胜人类对手的AI,其中涵盖精英人类专业人士,对于AI机器人而言,这通常被视作‘超人’的表现。
研究者宣称,他们用以构建Pluribus的算法,无法确保在双人零和游戏以外收敛至纳什均衡。即便如此,他们留意到Pluribus于六人扑克里的策略,始终能够战胜职业玩家,所以这些算法,能够在双人零和游戏以外的更为宽泛的场景当中,生成超人类的策略。
更复杂环境中的隐藏信息
不存在别的游戏,像扑克这般有着如此大隐藏信息方面的挑战,每个玩家都持有别的玩家所没有的信息,也就是自身的牌面,一个成功的扑克AI得对这个隐藏的信息进行推理,并且慎重地平衡自身策略,目的是保持不可预测,与此同时还要采取良好的行动。
比如说,bluff有时会起到作用,然而老是进行bluff就极易被察觉,进而致使损失诸多资金。所以,有必要审慎衡量bluff的概率以及强牌下注的概率。也就是说,在不完美信息游戏里动作的值是由其被选中的概率和选择别的动作的概率所决定的。
与此相反,于完美信息游戏里,玩家无需担忧平衡动作所具有的概率。而在国际象棋当中,那些好的动作,不管其被选择的概率究竟怎样,统统都是好的。
像此前 Libratus 这般的扑克 AI,在两款玩家无限制德州扑克游戏这类游戏里,借助基于 Counterfactual Regret Minimization(CFR)从理论层面来讲合理的自身游戏运用的算法,与审慎进行构想设计的搜索程序相互结合,去处理游戏内的潜藏信息问题了。
然而,往扑克里增添额外的玩家,会以指数的方式,令游戏的复杂性增加 若计算量多达10,000倍 以前的那些技术 是无法扩展至六人扑克的。
Pluribus所运用的新技术,能够比以往的任何事物,都更出色地应对这一挑战。
理解 Pluribus 的蓝图策略
Pluribus的核心策略,是借由自我博弈的方式来学习,在这个过程里,AI和自身展开对战,不把任何人类游戏数据用作输入,AI先是随机地挑选玩法,随后,在决定每一步的行动之后,渐渐提升性能,还给这些行动拟合概率分布,最终,AI的表现会比先前的策略版本更佳,Pluribus中的自我博弈策略乃是一种改进版本的蒙特卡洛CFR(MCCFR)。
在每一回的迭代之际,MCCFR 将其中的一方指定为‘traverser’对象,于迭代期间对这一方的当前策略予以更新。在迭代起始之时,凭借所有玩家的当前策略(最初系全然随机的),MCCFR 模拟出一副扑克。当模拟完毕的时候,算法对‘traverser’对象的每一个策略加以回顾,并且计算要是选取其他的行动,其胜率会在多大程度上得到提升或者下降。随后,AI 再去评估依据这一决策施行之后,接下来的每个假设决策的优势,如此这般,一一类推。
探寻别的假设所产生的结果具备可能性,这是源于AI是进行自我对弈的。要是AI期望知晓其他选择往后会出现什么情况,它仅仅只需询问自身该如何去回应这些行为。
被加入到反事实后悔行为中的有,‘traverser’对象实际做了什么选择与可能做什么选择之间存在的差异。在迭代结束时,‘traverser’对象的策略得到更新。所以,有着更高反事实后悔概率的选择被选中。在德州扑克这种没有限制的游戏里德信竞技,保持每一个行动中的策略所需的字节数,超过了整个宇宙的原子数。研究人员要求AI为减少游戏复杂度而忽略一些行动,且使用一种抽象方法把类似的决策点聚合在一起,在这抽象之后,聚合的决策点被视作是独一无二的。
被称作蓝图策略的是Pluribus的自我博弈后果,在实际的游戏里头,Pluribus运用搜索算法去提升这一蓝图策略,然而Pluribus不会依照从对手那里观察到的倾向来调整其策略。
这幅图呈现出,Pluribus 的蓝图策略于训练进程里是怎样逐步得以改进的,其性能借助训练的最终快照予以评估,研究者在这般比较之际并未进行搜索,而是按照与人类专业玩家论述,针对普通人类玩家以及顶级人类玩家的表现加以评估,该图还表明了 Pluribus 何时终止 limping,而 limping 乃是高级人类玩家通常会予以规避的一种打法。
研究人员训练蓝图策略花费了8天时间,使用的是一个64核的服务器,所需内存数量小于512G,他们并未使用GPU,在典型的云计算模式下,这仅需150美元,与其他AI研究相比,涵盖其他自我对弈的AI而言,此种消耗甚是微小,鉴于算法方面的提升,研究人员能够在成本较低的计算环境达成极大的性能提升。
更高效的搜索策略
基于无限制德州扑克具备的规模以及复杂性,蓝图策略必然得是粗粒度的喽,在实际的进程当中,Pluribus借助实时搜索来改进蓝图策略,从而针对特定情形去确定更好且更细粒度的策略呢。
AI bot时常于诸多完美信息博弈里运用实时搜索,其中涵盖西洋双陆棋也就是two – ply search,还有国际象棋即alpha – beta pruning search,以及围棋是Monte Carlo tree search。比如说,当模型在抉择下一步要采取哪一步行动的时候,国际象棋的AI一般情况下会思索往后的某些移动步骤,直至算法的前瞻延伸至叶节点或者达到深度的上限之处。
可是,这些搜索办法并不契合不完美信息博弈,况且它们根本不考量对手转移至叶节点以外策略的能力。这个弱点致使搜索算法生成了不坚固的、不均衡的策略,进而让对手迅速察觉这个失误。AI bot 在以往也就无法把博弈延展到6个参与者。
相反,Pluribus采用一种新办法,当中搜索器确切地考量了不完美信息博弈的实际情形,也就是任何参与者皆能够转移至子博弈外的叶节点策略上。具体来讲,研究者并未假定所有参与者都得依据叶节点之外的单个固定策略来进行博弈,这会致使叶节点仅有单个固定值。在搜索已抵达叶节点时,研究者假定每一个参与者会从四个不同的策略里作出选择,去进行剩余的博弈。
研究者于Pluribus中所运用的四个延续策略为:预计算的蓝图策略,在此蓝图策略基础上加以修改,从而使策略偏置至弃牌,修改蓝图策略以使它偏置至叫牌,修改蓝图策略以使它偏置至加注。
这种技术能够让搜索器寻觅到一种更为均衡的策略,进而在整体性能之处展示得更优,由于挑选不平衡的策略会致使对手转向别的延续策略,进而产生惩罚,比如说玩石头剪刀布时,我仅出石头,那么对手必定能够学习到只出布的策略。
恰如研究者所表明的,于搜索不完全信息博弈之际,另外一个面临的挑战在于,参与者针对特定情形的最优策略,是取决于其对手有关玩法对于它的看法的 ,比如说打德州扑克,要是一个参与者始终都不会进行虚张声势的行为,那么处于这种情况下,其对手总归能够知晓在面临加大赌注这一状况要做出丢弃手牌退出牌局行动的。
为此应对这般情形,Pluribus依托自身策略,于每一手中追踪当下状况之出现概率。不论它实际上处于哪一手,Pluribus首先皆会预测每一手时即将采取之行动——进而小心翼翼地于所有手时平衡自身策略,致使人类玩家难以预测其下一步行动。一旦算得这一涵盖所有手的平衡策略,Pluribus随后便会为它实际所在之手执行一项操作。
赛中,Pluribus于两个CPU上运行,相较,2016年与李世石对弈之围棋赛里,AlphaGo动用了1920块CPU及280块GPU,同时,Pluribus使用内存不多于128GB,于对每一子分支搜索之际,依现场状况,其用时介于1秒至33秒间。Pluribus的游戏耗时相较于人类专业玩家快出两倍,于六人游戏场景里,并在与自身进行对弈之际,它平均每一手所需时间仅为20秒。
Pluribus 与人类玩家的对抗效果如何?
研究者让Pluribus和一群人类顶级扑克玩家进行对抗,以此来评估它在实际作战中的效果,这些玩家包含‘耶稣’Chris Ferguson,他是2000年世界扑克系列赛主赛事冠军,还有Greg Merson,他是2012年世界扑克系列赛主赛事冠军,以及Darren Elias,他是四届世界扑克巡回赛冠军。下面是人类玩家的整个完整名单,分别是:Jimmy Chou,Seth Davies,Michael Gagliano,Anthony Gregg,Dong Kim,Jason Les,Linus Loeliger,Daniel McAulay,Nick Petrangelo,Sean Ruane,Trevor Savage以及Jake Toole。
当AI系统于其他基准游戏里跟人类展开对战时,机器有时在起始阶段表现甚好,然而随着人类玩家发觉它们的弱点,最终便会将它们击败。要是AI想要完全掌控一场游戏,它得展现出这样一种能力,就是即便人类玩家能够渐渐适应它们的节奏,可它们依旧能获取胜利。过去几天,职业扑克玩家和Pluribus进行了数千场比赛,所以有充足的时间去找出它的弱点,进而渐渐适应它。
Elias讲了这样一番话语,其内容为,Pluribus处于一种状况,那就是在跟全球范围内最佳的扑克玩家展开对抗呀。
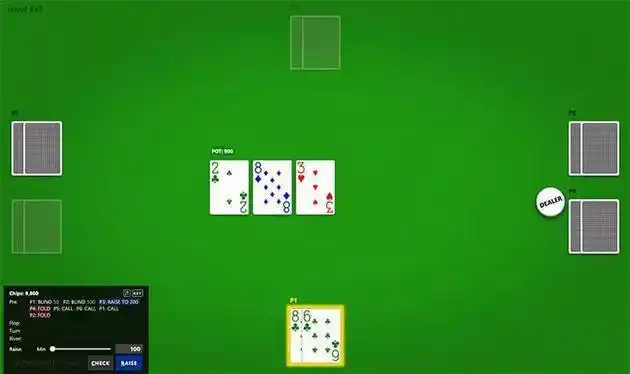
以下是实验中 Pluribus 与人类玩家对抗时的界面:
实验存在两种模式,其一,是 5 名人类玩家同 1 个 AI 展开对抗;其二,为 1 名人类玩家和 5 个 AI 副本进行对抗。所以,在每一种对抗模式当中,都有 6 名玩家参与进去,而且每局开始之际有 10000 筹码。小盲也就是 small blind 为 50 筹码,大盲即 big blind 是 100 筹码。
虽说扑克属于一款依赖技巧的游戏,然而其中却存在着相当大的运气因素。要是运气不好,哪怕是顶级职业玩家,在 10000 手的扑克赛事里也会出现输钱的情况。为了降低运气成分在扑克比赛里所起的作用,研究者采用了一种名为 AIVAT 的方差缩减算法,这种算法针对各种状况的值展开基线估计,以此在维持样本无偏的情况下缩减方差。比如说,要是 Pluribus 拿到一副强势的手牌,AIVAT 就会从其赢得之中减去基准值,借此对抗好运气。
5 名人类玩家+1 个 AI
在那场实验里,有着人类玩家与AI之间所展开的10000手扑克比赛情形,该比赛持续了长达12天时间,每天会针对性挑选5名人类玩家去跟AI开展比赛。那些玩家会基于自身呈现出来的表现状况来瓜分50000美元的奖励,以此形式激励他们发挥出自身最佳水平。在采用AIVAT之后,Pluribus存在的胜率预计大约是每100手有5个大盲注 ,括号里标注标准误差为5 bb/100,这对于顶级人类扑克玩家来讲是极为巨大的胜利 ,括号里盈利P值为0.021。所以,要是每个筹码价值为 1 美元,Pluribus 每手平均能够赢 得 5 美元,每小时可以赢 得 1000 美元。这样的一个结果超出了纯职业玩家在与职业的以及业余两者混合玩家对抗的时候的胜率。
弗格森在那场比赛实验结束之后讲道,“普卢里布斯”真的极其难以应对,我们很难在任何一次出牌当中盯住它,它不但极为擅长开展薄的价值下注,并且善于从好的手牌里面获取最大价值。
不过,需要留意的是,Pluribus 的原本意图是要成为人工智能研究的工具,而研究者只是把扑克比赛当作一种途径,借此去测量人工智能在不完全信息多智能体交互方面(这与人类顶级能力存在关联)所取得的进展。
5 个 AI+1 个人类玩家
很多人公认的六人无限德扑顶级玩家 Loeliger 参与了实验,参与实验的还有 Ferguson、Elias。每个人要与五个 Pluribus AI 玩 5000 手扑克。Pluribus 未根据对手情况调整策略,所以机器人之间的故意勾结并非问题。总的来讲,人类每 100 手会损失 2.3 bb。Elias,以每100手计,损失4.0 bb,其标准误差为2.2 bb/100,Ferguson,每100手会损失2.5bb,标准误差同样为2.2 bb/100,Loeliger,每100手损失0.5 bb,标准误差是1.0 bb/100。
这张图呈现出了,Pluribus在10000手实验之时,针对职业扑克玩家的平均胜率情况。其中,直线所代表的乃实际得到的结果,而虚线所代表的则是一个标准差情形。

“这个AI最为突出的优点便是其运用混合策略的本领,”Elias声称。“人类也期望如此去做。对于人类而言,这是一个执行方面的问题——要以一种全然随机的方式持续开展。大多数人类无法达成这一点。”。
鉴于Pluribus的策略全然是于不存在任何人类数据的情形下借助self-play自行习得的,所以它也给出了一个外部视角,也就是在多人无限制德州扑克游戏里最好的玩法理应呈现出何种模样。
Pluribus证实了,人类传统的挺有趣玩法,即叫大盲而非加注或弃牌,对除小盲外的任一玩家而言,都并非最佳策略,因依规则,小盲已下了大盲的一半,所以小盲跟注只需再下一半。
虽然Pluribus最开始处于通过self – play离线计算蓝图策略之际尝试limping行为,可是伴随self – play持续进行,它渐渐舍弃了该策略。
而且呢,Pluribus可不认可donk视为一种错误的想法,(在前面那一轮投注告终的时候,开启新的一轮加注),和专业人员展开比较而言,Pluribus更偏向于此种做法。
在和扑克AI展开比赛期间,目睹它所选用的某些策略,着实是特别令人感到过瘾,Gagliano如此说道。存在几场比赛,人类根本就未曾发挥出任何作用,尤其是在它下注情形颇为狠辣的那几场比赛当中。

此刻呈现相关的这张图,其展示的是,在处于和顶尖玩家进行对战这个特定情境之下,Pluribus 的筹码数量所发生的变化情况。其中,直线所代表的是实际出现的结果,而虚线所代表的则是相当于一个标准差的情况。
从扑克到其它不完美信息博弈的挑战
在以前,AI 于完美信息零和博弈(针对两个参与者)里,多次取得了引人注目的成功。然而,大多数真实世界的策略交互,涉及隐信息,并且并非是两个参与者的零和博弈。Pluribus 的成功显示出,当下存在更大规模的、极其复杂的多参与者场景,仔细构建的自我博弈和搜索算法,能够在这些场景下获得良好的效果,尽管当前不存在很强的理论支持来确保这个效果。
Pluribus别具一格,鉴于同其他近期的AI系统相较,于基准博弈里,其训练以及推断成本均更为低廉。虽说该领域部分研究者忧虑将来的AI研究将由具备大量计算资源的大型团队掌控。然而研究者坚信Pluribus是个有力证据,表明新方法只需恰当的计算资源,便可推动顶尖的AI研究。
不管 Pluribus 旨在为了玩扑克而开发,然而其运用的技术并非扑克所特有的,它也无需任何专家领域的知识来开展开发。这项研究给咱们给予了一个更佳的基本理解,也就是怎样构建普遍的 AI 去应对多智能体环境,这般环境既涵盖其它 AI 智能体,又涵盖人类。与此同时,搭建普遍的多智能体 AI,还能够使得研究人员把研究流程中获取的 AI 基准成绩跟人类能力的尖峰作对比。
当然,于Pluribus里采取的办法,或许并不会在全部多智能体设定之上收获成功。在扑克当中,参与的一方很难拥有与别的智能体交流的机会,这存在构建极为简单的调和博弈的可能性,所以self – play算法寻觅不到一个良好的策略。
然而,对于诸多现实世界的交互举动,其中涵盖反欺诈、网络安全以及内容审核等方面,潜在地都能够借助Pluribus的方法来实施建模。也就是说,将其建模为包含隐藏信息的场景,并且(或者)借助多个智能体之间的有限交流,以此来搭建不同参与方之间的联系。而这项用于打德州扑克的技术,甚至能够让Pluribus助力AI社区,在不同领域之中构建更为高效的策略。
最后,在过去十六年里,Tuomas Sandholm 以及 CMU 团队一直在钻研策略推理技术。Pluribus 构建与融合了策略推理多数技术码,但它也涵盖扑克专门代码,这些代码由 CMU 与 Facebook 合作完成,并且不会应用于国防方面。
